TL;DR: We’ve created VAKER, a new system that solves a major problem in AI video generation: creating videos with clear, readable text and precise control over animated elements. Unlike existing models that struggle with text rendering, VAKER treats video layouts as structured text representations and uses a three-stage process to generate visually appealing video advertisements with dynamic text animations.

Introducing Animated Layout Generation
While text-to-video models have made impressive advances in creating realistic scenes, they still struggle with two critical challenges: generating readable text and precisely controlling animated graphics. Our work addresses these limitations with a novel approach we call Animated Layout Generation.
The Challenge
Current diffusion-based text-to-video models excel at generating diverse videos with realistic scenes, but they have a fundamental constraint: they can’t reliably produce readable text or precisely position animated elements. This limitation becomes particularly apparent when trying to create content like:
- Social media videos with animated captions
- Promotional videos with precisely timed visual elements
- Informational videos with synchronized text overlays
Our Solution: VAKER
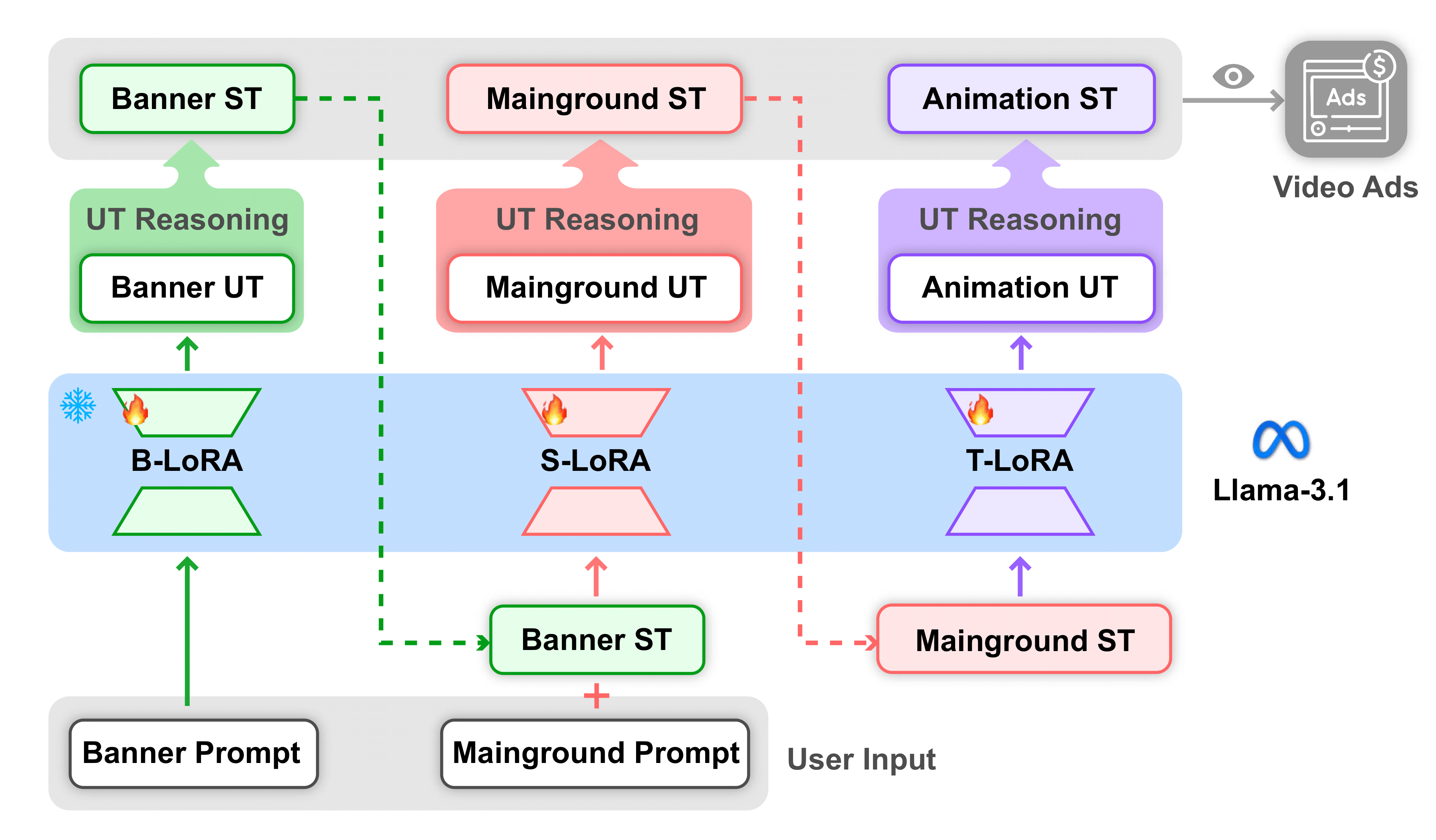
To address these challenges, we’ve developed VAKER (Video Ad maKER), a comprehensive text-to-video advertisement generation pipeline. VAKER introduces several properties:
Structured Text (ST) Representation: A novel way to represent videos as hierarchical text sequences, preserving spatial and temporal relationship while enabling precise control over text rendering and object positioning
Three-Stage Generation Process: VAKER breaks the complex task of video advertisement creation into three manageable stages:
- Banner generation (texts at the bottom/top of the screen)
- Mainground generation (background and foreground elements)
- Animation generation (defining how elements move over time)
Unstructured Text (UT) Reasoning: A Chain-of-Thought approach that leverages the reasoning capabilities of LLMs to translate natural language prompts into structured formats.
Results
For video results, please check our project page. VAKER can create diverse animation patterns, including:
- Horizontal/vertical shifts
- Spiral reveals
- Pulsing effects
- Expansions and contractions
- Growth/shrinking animations

What’s particularly interesting is that several of these animation patterns emerged without explicit training examples, demonstrating the model’s generative capabilities.
Technical Implementation
VAKER is powered by a LoRA-adapted Llama-3.1 70B model, trained on a dataset of 2,224 video advertisements (provided by SK telecom, preprocessed ourselves). The training process involves fine-tuning three specialized expert models, each handling a different stage of the generation process.